Introduction
I've spent countless hours trying to find the right OCR tool for different projects. You know the drill—you Google "best OCR software," read a dozen listicles with conflicting recommendations, download three different tools, test them on your documents, and still aren't sure which one actually works best. It's exhausting and inefficient.
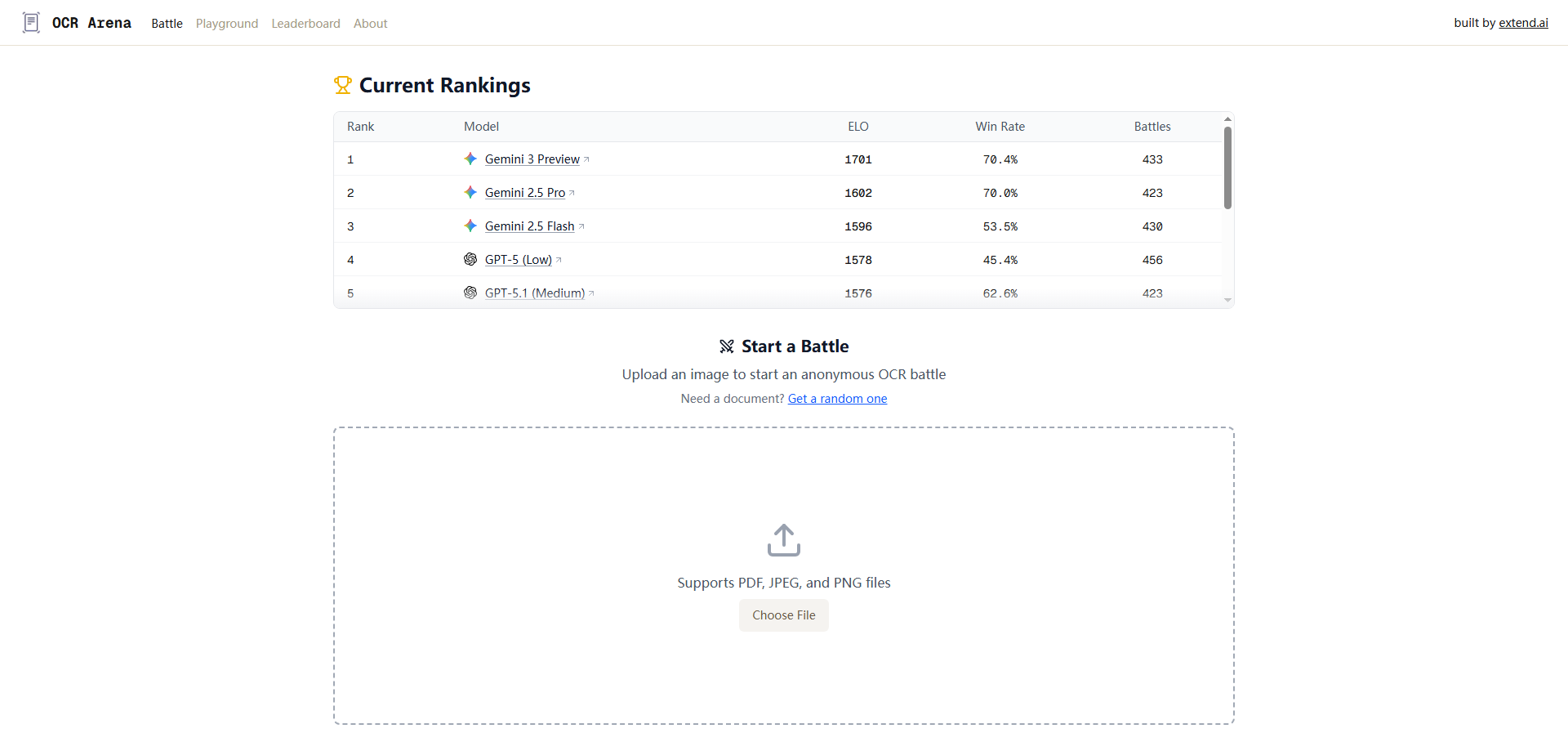
That's why OCR Arena immediately grabbed my attention. It's positioning itself as the world's first public OCR leaderboard, and the concept is beautifully simple: upload any document, watch multiple top OCR and vision language models process it simultaneously, compare their accuracy side-by-side, and vote for the best one. It's like creating a competitive arena where AI models battle it out on your actual documents, not just abstract benchmarks.
Let me walk you through why I think this approach to OCR evaluation is genuinely creative, whether it can disrupt how we choose document recognition tools, and whether it has what it takes to survive in a niche but important market.
The Creative Breakthrough: Democratizing AI Model Evaluation
What excites me most about OCR Arena is how it democratizes something that's traditionally been locked away in academic labs and corporate R&D departments—rigorous AI model evaluation.
The creative insight here is recognizing that existing OCR benchmarks don't reflect real-world use cases. Academic papers test models on standardized datasets that might not look anything like the blurry receipt you just photographed or the handwritten note you need to digitize. OCR Arena says, "Forget artificial benchmarks. Bring your actual documents, and we'll show you which models actually work for your specific needs."
This user-generated evaluation approach is brilliant because it creates a virtuous cycle. As more people upload diverse documents—receipts, contracts, screenshots, handwritten notes, old scanned books, forms with checkboxes, multi-language documents—the platform builds a real-world performance profile for each model. The leaderboard isn't based on some researcher's curated test set; it's based on actual human judgments about which models handled real documents better.
The voting mechanism is clever too. Instead of relying solely on automated metrics like character error rate, OCR Arena lets humans vote for the model they think performed best. This is smart because OCR quality isn't just about technical accuracy—it's about practical usefulness. A model might technically misread one character but still produce perfectly usable output, while another might get every character technically correct but format things so badly that the result is unusable. Human voting captures these nuances.
What I find particularly creative is positioning this as a free public platform rather than a paid service. By making OCR model comparison free and accessible, they're doing two things: first, lowering the barrier for anyone who needs OCR to find the best tool for their needs; and second, gathering massive amounts of comparative data that could become incredibly valuable for understanding OCR model strengths and weaknesses across different document types.
The comparison interface—showing multiple model outputs side-by-side—is simple but effective. I can immediately see which model handled that smudged signature better, which one correctly captured the table structure, or which one completely botched the formatting. This visual, comparative approach is far more intuitive than reading technical specifications about model architectures.
The inclusion of both OCR models and vision language models (VLMs) shows forward-thinking. Traditional OCR just extracts text. VLMs can understand context, interpret layouts, and even answer questions about document content. By comparing both categories on the same platform, OCR Arena is acknowledging that document understanding is evolving beyond simple text extraction.
From a creative standpoint, OCR Arena is essentially applying the "arena" or "battle" format that's worked well for LLM leaderboards like Chatbot Arena to the OCR domain. It's not a completely novel concept, but the execution for OCR specifically is fresh, and the focus on real user documents rather than academic datasets is genuinely innovative.
Can It Disrupt OCR Tool Selection?
Now let's talk disruption. OCR isn't a new field—it's been around for decades. We have established tools like Adobe Acrobat, ABBYY FineReader, Google Cloud Vision, AWS Textract, and dozens of others. Can OCR Arena actually change how people choose and use these tools?
I think the answer is yes, but in specific ways rather than complete replacement of existing solutions.
What OCR Arena Could Replace:
First, it could replace the frustrating trial-and-error process of OCR tool selection. Right now, if I need OCR for a project, I either go with a big name (Adobe, Google) and hope it works, or I spend days testing different options. OCR Arena compresses that discovery process into minutes. Upload a representative sample document, see which models perform best, then go subscribe to that service. That's incredibly valuable.
Second, it could disrupt OCR review sites and comparison articles. Those "Top 10 OCR Tools of 2024" listicles are often outdated, biased toward paid sponsors, or based on superficial testing. OCR Arena provides real, transparent, user-driven comparisons that are constantly updated as models improve and new ones emerge. Why would I trust a random blog post when I can test on my actual documents?
Third, for developers choosing OCR APIs for their applications, OCR Arena could replace expensive testing and evaluation processes. Instead of subscribing to three different OCR services to test them, a developer could upload sample documents to OCR Arena, see which APIs perform best, and make an informed decision before committing money.
Fourth, it could partially replace academic benchmarking for practitioners. Researchers will still need rigorous, controlled benchmarks, but for practitioners who just want to know "which OCR works best for invoices" or "which VLM handles handwriting better," OCR Arena provides faster, more practical answers.
What It Won't Replace:
Let's be clear—OCR Arena isn't an OCR service itself. It won't replace actual OCR tools like Tesseract, Google Cloud Vision, or Adobe Acrobat. You still need those services to actually process your documents at scale. OCR Arena is a discovery and evaluation layer, not a production tool.
It also won't replace specialized OCR testing for enterprise deployments. Large companies with specific compliance requirements, security concerns, or unique document types will still need thorough internal testing before choosing an OCR solution. OCR Arena can inform that process but won't replace it entirely.
And it won't replace domain-specific OCR benchmarks for specialized use cases like medical records, historical manuscripts, or scientific documents, where evaluation requires expert knowledge that crowdsourced voting can't provide.
The disruption I see is in the discovery and evaluation phase of OCR tool selection. OCR Arena makes it dramatically easier to answer the question "which OCR should I use?" That's valuable even if it doesn't change the actual OCR tools people ultimately use.
The potential broader disruption is creating a new category: public, transparent, user-driven AI model leaderboards for specialized tasks. If OCR Arena succeeds, we might see similar platforms for speech recognition, image generation, translation models, and other AI capabilities where choosing the right tool is currently difficult.
User Acceptance: Who Needs This?
This is the critical question. Is there real demand for OCR model comparison? Will people actually use OCR Arena?
Based on my analysis, I see several user segments with genuine needs:
Segment 1: Developers and Technical Decision-Makers
Developers building applications that need OCR capabilities face a real problem: which API should they integrate? This choice has significant cost and technical implications. The wrong OCR can mean poor user experiences, higher API costs, or failed accuracy requirements.
For this segment, OCR Arena is incredibly valuable. Being able to quickly test different OCR models on representative documents before committing to an API could save thousands of dollars in wasted integration efforts and API fees. I'd expect strong adoption here.
The challenge is whether the models available on OCR Arena match the APIs they're actually considering. If Arena only tests open-source models but developers need to choose between Google, AWS, and Azure OCR services, the value is limited.
Segment 2: Students and Researchers
Anyone working on OCR research, document digitization projects, or studying computer vision needs to understand the current state of the art. OCR Arena provides a real-time snapshot of model capabilities across different document types.
User acceptance here depends on academic credibility. If Arena's methodology is rigorous and transparent, it could become a cited reference. If it's seen as too casual or unscientific, academics might ignore it.
Segment 3: Small Business Owners and Freelancers
Small businesses that need to digitize receipts, invoices, contracts, or other documents often can't afford expensive OCR software. They need to find free or cheap solutions that actually work for their specific document types.
OCR Arena could be perfect for this segment—test your actual business documents on multiple free OCR options, see which works best, then use that one. This is practical, cost-effective guidance.
The barrier here is awareness. Small business owners aren't browsing Product Hunt looking for OCR evaluation platforms. OCR Arena needs strong SEO and word-of-mouth to reach this audience.
Segment 4: Individual Users with One-Off Needs
Sometimes you just need to digitize a single document—a recipe from an old cookbook, a contract your landlord sent, a handwritten note. You don't want to research OCR tools; you just want something that works.
For these users, OCR Arena is helpful but maybe not essential. They might just use whatever OCR comes built into their phone or the first free tool they find. Still, if OCR Arena ranks high in search results for "free OCR," it could capture this traffic.
Barriers to Acceptance:
The biggest barrier I see is the "just tell me which one to use" problem. Some users want recommendations, not comparisons. They don't want to upload documents and evaluate results themselves; they want someone to say "use this OCR for receipts, this one for contracts." OCR Arena requires active participation, which some users might find too effortful.
Second, there's the learning curve. Understanding the difference between OCR models and VLMs, interpreting comparison results, and knowing which metrics matter requires some technical sophistication. The platform needs excellent UX to make evaluation accessible to non-technical users.
Third, privacy concerns could limit adoption. Users might be hesitant to upload sensitive documents—medical records, financial statements, legal contracts—to a free public platform. Even if Arena promises not to store documents, perception matters.
Finally, with only 137 upvotes and 7 discussions on Product Hunt, the initial traction is modest. That could indicate limited immediate demand or could mean the marketing hasn't reached the right audience yet.
Overall, I'd rate user acceptance potential as moderate to high among developers and technical users, moderate among researchers and small businesses, and lower among general consumers. That's still a viable market if they focus on the high-value segments.
Survival Rating and Risk Assessment: 3.5 Stars
If I'm rating OCR Arena's chances of surviving and growing over the next year, I'm giving it 3.5 out of 5 stars. I'm cautiously optimistic but see both significant opportunities and real challenges.
The Opportunities:
First, OCR is a growing market. As businesses digitize operations and AI capabilities expand, demand for document understanding is increasing. More people need OCR, which means more people need help choosing the right OCR solution. OCR Arena is well-positioned to capture this need.
Second, the transparency and open evaluation approach aligns with broader trends in AI. People are increasingly skeptical of opaque AI systems and want to understand model capabilities. Public leaderboards that anyone can contribute to build trust and credibility.
Third, the data OCR Arena collects could become incredibly valuable. Understanding which OCR models perform best on different document types—receipts vs. contracts vs. handwritten notes vs. technical diagrams—is insights that researchers, OCR developers, and businesses would pay for. There's a potential business model in selling aggregated performance analytics.
Fourth, being "the world's first OCR leaderboard" gives them first-mover advantage and media hook. If they can become the go-to reference for OCR model performance, they establish a moat that's hard for competitors to overcome.
Fifth, the free model removes barriers to adoption. People can try it without risk, which encourages experimentation and word-of-mouth growth.
The Risks:
The most significant risk is sustainability. How does a free platform with 137 users generate enough revenue to survive? Running OCR comparisons requires computational resources—processing user documents through multiple models costs money. Without clear monetization, they could run out of funding before achieving scale.
Second, there's the quality control challenge. If anyone can upload any document and vote, how do they prevent spam, gaming the system, or low-quality data polluting the leaderboard? Bad actors could intentionally vote for inferior models to manipulate rankings. They need robust verification and anti-abuse mechanisms.
Third, model providers might not cooperate. If Google, Adobe, or AWS don't want their OCR services included in public comparisons (especially if they perform poorly), they could send cease and desist letters or cut off API access. OCR Arena needs either explicit partnerships or to limit comparisons to models that welcome public evaluation.
Fourth, the 7 discussions on Product Hunt suggest limited viral potential. If people aren't talking about it, sharing it, or building community around it, growth will be slow. They need to generate more engagement and user-generated content.
Fifth, there's competition risk. If the concept proves valuable, established players like Hugging Face, Papers with Code, or even Google could launch similar leaderboards with more resources and distribution. First-mover advantage only lasts if you move fast enough to build defensible scale.
Sixth, technical execution is critical. If the platform is slow, produces inaccurate comparisons, or has poor UX, users won't return. The comparison methodology needs to be sound and the results trustworthy.
Finally, niche market risk is real. OCR evaluation is important but narrow. Unlike general LLM leaderboards that appeal to millions, OCR Arena might struggle to grow beyond a core community of thousands or tens of thousands. That might be enough to survive but not enough to thrive.
My Prediction:
I think OCR Arena will survive the next year if they can achieve two things: first, establish themselves as the authoritative source for OCR model performance among developers and researchers; and second, find a sustainable business model—whether that's premium features, enterprise licensing, data analytics sales, or affiliate partnerships with OCR service providers.
The realistic scenario is building a dedicated community of 5,000-20,000 active users who regularly use Arena for OCR evaluation. That's enough to prove value and justify continued investment, even if it's not hockey-stick growth.
The path to success involves: aggressive content marketing and SEO to capture people searching for OCR comparisons; building integrations or partnerships with developer platforms; ensuring rock-solid methodology that developers trust; and creating a community around OCR evaluation—maybe forums, case studies, or annual reports on OCR model evolution.
The path to failure is: running out of money before achieving sustainable revenue; quality problems that undermine credibility; or simply failing to grow beyond the initial early adopter group.
I'm giving it 3.5 stars because the concept is sound, the market need is real, and the execution seems competent. But the challenges are substantial, particularly around monetization and scaling beyond a niche audience.
Conclusion
After thoroughly analyzing OCR Arena, I'm genuinely impressed by the creative approach to a real problem. Making OCR model evaluation accessible, transparent, and user-driven is valuable innovation in a space that's traditionally been opaque and inaccessible.
The potential to disrupt OCR tool selection and evaluation is real, even if OCR Arena won't replace the actual OCR services themselves. For developers, researchers, and businesses trying to choose the right document recognition solution, this platform could become an indispensable resource.
User acceptance looks promising among technical audiences—developers and researchers who understand AI models and need practical guidance on which tools work best. Adoption among general consumers will be more challenging and might require simplification of the interface and messaging.
My 3.5-star survival rating reflects realistic optimism. The opportunities are genuine—growing OCR market, demand for transparency, valuable data collection, and first-mover advantage. But the risks are equally real—monetization challenges, quality control, competition, and limited viral potential.
If I were advising the OCR Arena team, I'd say: focus obsessively on developer adoption first. Build credibility by ensuring comparison methodology is rigorous and results are trustworthy. Publish detailed performance reports for different document types to drive SEO and establish authority. Explore partnerships with OCR service providers who want independent validation. And most critically, find revenue before you run out of runway—whether that's premium analytics, enterprise features, or consulting services.
The world genuinely needs better tools for evaluating OCR models. Too many people waste time and money choosing the wrong solution because they lack good comparison tools. If OCR Arena can become the trusted, go-to platform for OCR evaluation, they'll have built something valuable and sustainable.
I'm cautiously optimistic they can pull it off, but the next year will be critical. They need to prove that a free, public OCR leaderboard can attract enough users and generate enough value to justify continued operation. That's entirely possible, but far from guaranteed.